


7 Synthetic Data Companies for Training AI Models




Table of contents

Last year, we opted to exit our position in Appen (APX.AX), an Australian company whose core business involves annotating and labeling training data for AI models. It turned out to be a good decision: Appen has lost nearly -70% in the last year, compared to +38% for the NASDAQ during that time. Our main argument against the company centered on the sustainability of using manual labor for big data labeling as a service. That’s becoming even more apparent with the rise of synthetic data companies that can generate training data for AI models at a fraction of what it costs to have humans screw it up do it with real-world data.
What is Synthetic Data?
This isn’t exactly a new topic for us. A couple of years ago we featured a Singapore startup called CVEDIA that creates photorealistic, labeled 3D worlds for training, testing, and validating machine learning algorithms. We followed that article with one that dug deeper into the nuts and bolts of synthetic data by highlighting some of the platforms currently on the market. For this article, we’ll provide an updated definition of synthetic data we came across from the world’s leading AI chip company, Nvidia (NVDA):
Synthetic data is annotated information that computer simulations or algorithms generate as an alternative to real-world data. Put another way, synthetic data is created in digital worlds rather than collected from or measured in the real world.
In fact, Nvidia has developed a simulation platform called Omniverse where diverse businesses can build or collaborate on AI projects using synthetic data and other tools. For example, Nvidia created an application in Omniverse called Isaac Sim where users can train robots in this virtual world with synthetic data and then deploy the resulting software on real-world killer robots. Research suggests that not only is computer-generated data as effective as natural data in teaching robots skills like how to throttle someone grasp household objects, but they perform better in novel environments such as extreme lighting conditions that are hard to replicate with photos scrapped off someone’s Flickr account.
Use Cases for Synthetic Data
Developing software for robots is only one of many use cases for synthetic data. Many applications focus on training computer vision systems, such as synthetic datasets used by self-driving vehicles to learn how to drive. (And, yes, Nvidia has an app for that as well.) Natural language processing (NLP) is another domain under artificial intelligence that can leverage synthetic data to augment or replace natural data to train AI models. That’s exactly what an AI healthcare startup called Curai is doing behind the scenes to develop a platform capable of diagnosing patient problems through text and pictures.
Indeed, industry experts believe that synthetic data will become the go-to source for training AI models in the not-too-distant future. Gartner predicts that by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated.
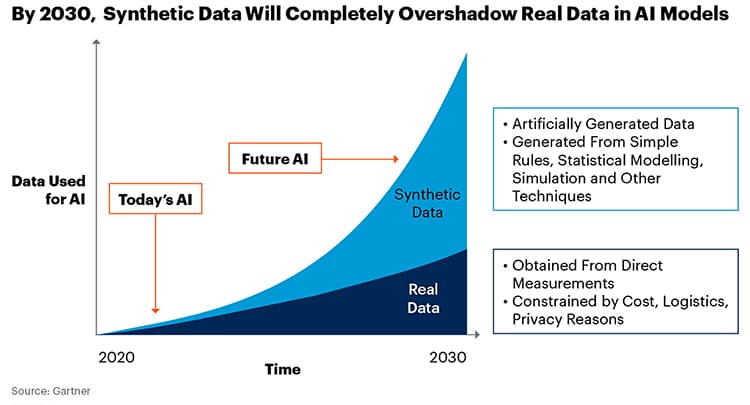
It really boils down (like most everything) to economics: A $6 image from a labeling service can be artificially generated for six cents. That’s according to Paul Walborsky, who co-founded synthetic data services startup AI.Reverie and was quoted in a Nvidia blog post on the topic.
Synthetic Data Companies
AI.Reverie is one of more than 50 synthetic data companies listed in this nifty market map from Elise Devaux, who works at Statice, a Berlin-based startup that specializes in synthetic data for privacy-preserving data applications – yet another use case for computer-generated data.

However, in this article, we’re going to focus on seven synthetic data startups that have taken funding in the last year or so to develop platforms that generate unstructured data to train AI models.
It’s Almost Human
Founded in 2018, Israeli startup Datagen has raised $22 million, including an $18.5 million Series A in February that qualified as the company’s official coming-out party. Datagen refers to its flavor of synthetic data as simulated data, as it specifically focuses on photorealistic visual simulations and recreations of the real world, with an apparent specialty in human motion. Like many synthetic data companies, Datagen relies on an increasingly popular AI technique called generative adversarial networks (GANs). It’s a bit like a chess game between two computer systems, but one is generating synthetic data while the other judges the authenticity of the result. The company combines GANs with something called Reinforcement Learning Humanoid Motion Algorithms within a Physical Simulator, along with super-rendering algorithms, to generate simulated data at scale.

Datagen is pursuing several markets, including augmented and virtual reality, Internet of Things, retail, robotics, and self-driving cars. For example, think retail automation in the form of an Amazon Go store, where the computer vision system tracks customers to ensure nobody walks away with any five-fingered discounts.
Update 03/24/2022: Datagen has raised $50 million in Series B funding to boost the growth of its synthetic data solution for computer vision (CV) teams. This brings the company’s total funding to $72 million to date.
Peek-A-Boo, AI Sees You
Probably one of the leading use cases today involves simulating environments for self-driving vehicles. That’s the core business behind Parallel Domain, a Silicon Valley startup founded in 2017 that we first covered a couple of years ago. The company has since raised about $13.9 million, including an $11 million Series A at the end of last year. Its biggest investor and customer is probably Toyota (TM). The company focuses its synthetic data platform on some of the most challenging use cases to teach self-driving cars how not to kill anyone. Its latest innovation, in collaboration with the Toyota Research Institute, involves using synthetic data to teach autonomous systems about object permanence. Current perception systems are like babies playing peek-a-boo, but partly thanks to Parallel Domain, AI can now track objects even when they temporarily disappear. The company also recently released its data visualizer to the public for fully labeled synthetic camera and LiDAR datasets:

In addition to autonomous driving, the company provides synthetic training data for autonomous drone delivery.
I Spy Synthetic Data
Founded in 2017, Mindtech is a UK startup that has raised about $6.5 million, including a $3.25 million Seed round just last month. One notable investor is In-Q-Tel, a U.S. government entity that invests in technologies that might someday benefit agencies like the CIA. So there’s that. Mindtech calls its end-to-end synthetic data platform Chameleon, a modular tool that enables users to quickly build unlimited scenes and scenarios using photo-realistic 3D models. The company says Chameleon is specifically designed to help its customers build AI models to “understand and predict human interactions.”

In addition to spy agencies, Mindtech is serving a variety of markets, including retail, smart home, healthcare, transportation systems, and robotics.
Look Out Below
Founded in 2017, we first covered New Yawk-based AI.Reverie back at the end of 2018. The company has disclosed $5.8 million in funding, including a $5.6 million Seed round in April 2020 that also included In-Q-Tel, as well as Vulcan Capital, the multi-billion dollar investment arm of Microsoft co-founder and formerly alive person Paul Allen. AI.Reverie claims its synthetic data performs nearly on par with real-world training data. And combining only 10% of natural data with the company’s computer-generated data provides better results than either one alone.

For example, the company has created RarePlanes, an openly available, very high-resolution dataset built to test the value of synthetic data from an overhead perspective. Experiments with RarePlanes showed that fine-tuning the synthetic-only model with 10% of the observed dataset achieved roughly the same results while eliminating 90% of the cost to manually collect and label real-world data.
Getting Some Synthetic Face Time
Founded in 2019, Synthesis AI raised $4.5 million in a Seed round back in April, with iRobot (IRBT) participating, presumably to improve its smart home robotic vacuums. Like Datagen, Synthesis is focused broadly on generating synthetic humans, using GANs and computer-generated image (CGI) technology found in just about every movie made today. The company’s first product is FaceAPI, which businesses can use to build more capable AI facial models for smartphone facial verification, teleconferencing, driver monitoring, and smart assistants.

In June, Synthesis AI released 40,000 unique high-resolution 3D facial models to improve AI models in terms of diverse facial types.
Automating Data Labeling
Founded in 2019, Synthetaic is a startup out of Wisconsin that has raised $4.5 million, including $1 million toward the end of last year. There’s not a lot of detail on the website about the company’s particular technology for creating synthetic data. Most of the information is about something called Rapid Automatic Image Categorization (RAIC), which seems to be an automated system for annotating images from a single labeled example. We did come across a news report about how the company’s GAN platform provided synthetic data to improve an AI model that diagnoses brain tumors from medical scans.

The results: The synthetic data boosted accuracy from 68% to 96% across major brain tumor types, including 90% performance on the most challenging cases versus 70%.
A Bird’s Eye View
Founded in 2019, OneView is an Israeli startup that has raised $3.5 million. The company focuses on providing synthetic data for AI models that provide geospatial intelligence from satellite and aerial images. These images often entail large swaths of the planet, including cities, airports, harbors, and much more. To build the base model for the synthetic dataset, OneView leverages real-world data from an open-source data mapping service called OpenStreetMap. You can read more about the process here, but basically, the company inflates a 2D image into a 3D one that it then renders multiple times to mimic different scenes, including objects, weather, lighting, etc.

OneView’s synthetic data can train AI models that serve a range of industries, from urban planning to insurance.
Conclusion
Data is the oil that drives AI engines. And we know that synthetic oil is better than conventional oil when it comes to engine performance. While that’s not entirely true of synthetic data in all cases, these and other companies are demonstrating that we’re close to replacing real-world data with a much cheaper, scalable alternative. All of the startups profiled here have been around for only four years or less, so we’re really at the dawn of this new market. While funding to these companies remains relatively modest, we’re already seeing an uptick in the size of funding rounds in less than a year. If companies like Nvidia and Toyota see value in this service, it’s only a matter of time before other big names join the oil rush.
Share








I think it would make a lot of sense for Appen to include in its offering generating synthetic data. So they should buy (or merge with) one of the synthetic data companies. Maybe now it could be difficult as their value fell 70% to $1.5B, but there is a very good chance their share price will recover in the second half of this year.
It’s not a bad idea, but which one? Did you see the size of that market map? That’s certainly one direction Appen can pivot into, perhaps acquiring a number of companies over time.
All these sound pretty good but these companies are not available to the average investor. We have to wait and see how good these companies would be in the future. Kudos to the research team and please let us know when these companies would be available to the average investor.
Thanks for the comment Patrick. It’s early days for these firms so anything becoming publicly traded is probably a long ways off. We’ll keep an eye on things though as we watch everything that goes public.